
Computer Vision: come l’Intelligenza Artificiale permette alle macchine di vedere, analizzare e comprendere
In questo articolo parleremo di una delle potenzialità più chiacchierate dell’Intelligenza Artificiale.
Al momento le aziende sono molto interessate a questa skill rispetto a tutte le altre come l’Analisi Predittiva e la Manutenzione Predittiva (che già fanno tanta gola alle aziende).
Bando alle ciance, questa skill si chiama Computer Vision o, per dirla in italiano, “visione computerizzata”.
Che cos’è la Computer Vision?
La Computer Vision è quel campo dell’intelligenza artificiale che dà alle macchine la capacità di “vedere”.
Con “vedere” si intende anche interpretare e comprendere le immagini.
Attraverso la Computer Vision, le macchine sono abilitate ad analizzare visivamente l’ambiente circostante o l’oggetto che stanno osservando, per estrarre informazioni utili.
Queste informazioni, a seconda del contesto, servono per fornire al sistema dei dati e quindi per svolgere diversi compiti.
Aspetta, aspetta… le macchine possono vedere come gli umani?
Per chiarire questo dubbio, facciamo un paragone con la visione umana.
Il nostro sistema visivo è formato dall’occhio che è in grado di raccogliere la luce, che passa per il nervo ottico e poi finisce nelle zone del cervello dedicate alla visione – il cosiddetto cervello visivo.
Una volta che queste informazioni sono arrivate al cervello, quest’ultimo associa un significato all’immagine in base all’esperienza della persona.
Per fare un esempio, un meccanico con 20 anni di esperienza osserva un pezzo meccanico e riesce probabilmente ad identificare eventuali difetti ad una velocità molto alta.
Allo stesso modo un radiologo che osserva una lastra radiografica o una tomografia al computer, molto probabilmente riconoscerà determinate patologie.
Quello che succede con la Computer Vision è qualcosa di simile, cioè diamo la capacità alla macchina di visualizzare le immagini e di comprenderne il significato.
Una macchina capace di ‘vedere’ saprebbe riconoscere un gatto siamese?
Prima di tutto, la macchina ha bisogno di imparare che cos’è un gatto.
Come detto prima con l’esempio del meccanico, noi esseri umani riconosciamo un gatto perché siamo abituati fin da piccoli a distinguere i vari animali attraverso immagini, esperienze concrete eccetera.
Poi magari impariamo a riconoscere un gatto siamese.
In poche parole, è un processo di apprendimento.
Perciò affinché una macchina sia in grado di riconoscere un gatto siamese, è necessario prima insegnare alla macchina a distinguere un gatto da un cane, ad esempio.
Poi una volta che si è abituata a questa differenza, si può andare più in profondità e insegnargli che quello è un gatto siamese.
In buona sostanza bisogna dare alla macchina un numero elevato di immagini di quello stesso gatto e far partire il processo di apprendimento o di training.
In realtà noi conviviamo con la Computer Vision in tasca ormai da anni…
Se non sai di che cosa stiamo parlando, di sicuro avrai sentito parlare del Face ID degli iPhone.
Ecco, quella è una forma di Computer Vision.
In questo caso specifico all’iPhone è già stato insegnato come riconoscere una faccia rispetto a qualsiasi altra immagine.
Dopodiché identifica le caratteristiche della faccia del proprietario e le memorizza.
Se volessimo fare un esempio più semplice, c’è il riconoscimento facciale (o Face Detection) delle macchine fotografiche, degli smartphone e così via.
Quando stai facendo una foto, all’improvviso si forma un quadratino sulle facce delle persone… e anche quella è una forma di Computer Vision.
C’è da aggiungere poi che nella Computer Vision per scopi professionali abbiamo dei sensori che hanno una potenzialità molto più alta rispetto a quella dell’occhio umano.
L’occhio umano è in grado di riconoscere solo lo spettro del visibile, che va dalla lunghezza d’onda del Rosso a quella del Violetto.
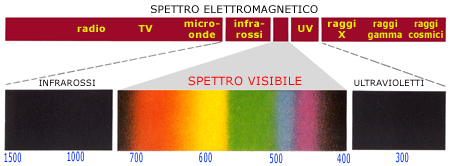
Un sensore ottico industriale è in grado di riconoscere delle lunghezze d’onde molto più ampie.
Per fare un esempio, per fare le tomografie un sensore ottico deve riuscire a ‘vedere’ lunghezze d’onda molto corte, come raggi gamma o raggi X, che servono anche per riconoscere all’interno di un oggetto.
Per “vedere” la temperatura corporea si parla di raggi ad infrarosso termico, che in questo periodo va molto di moda.
Alla fine, tutte queste informazioni che vengono riconosciute, poi possono essere utili per una grande variabilità di applicazioni pratiche.
Oppure, sempre in Cina, hanno installato ovunque possibile dei sistemi di riconoscimento facciale.
In poche parole, si tratta di tecnologie abbastanza consolidate.
Oggi, grazie alle potenze di calcolo disponibili, e anche ai sensori in grado di acquisire ad alta risoluzione sia a livello di immagine che a livello di radiazione elettromagnetica, si può arrivare ad applicazioni che fino a 10 anni fa erano impensabili.
Le funzioni più importanti della Computer Vision per le aziende a partire dal 2020
1) Un’evoluzione del controllo qualità
In ambito industriale il controllo qualità di solito si fa con sistemi di visione più tradizionali che non apprendono, ma identificano solo il problema.
Adesso si possono creare sistemi automatici di rilevamento anomalie (o ‘anomaly detection’) che nella produzione in serie permettono di identificare:
A) I pezzi da scartare.
B) Il tipo e l’entità dell’anomalia,
C) La causa che l’ha prodotta.
Questo porterà un netto miglioramento del controllo qualià che passerà, appunto, all’anomaly detection.
2) Boom di sistemi di riconoscimento delle patologie
In ambito medico stanno esplodendo, proprio in quest’ultimo periodo, i sistemi di riconoscimento di patologie partendo dalle immagini mediche.
Per fare un esempio, Paige è un’azienda americana che vuole sfruttare le potenzialità dell’Intelligenza Artificiale per:
►Perfezionare le diagnosi di cancro,
►Selezionare i trattamenti più adatti,
►Sostenere lo sviluppo di nuovi farmaci.
Citando VentureBeat: “L’idea è quella di usare i dataset relativi ai trattamenti e alla genomica per trainare le reti di deep learning aziendali e diagnosticare il cancro al seno, alla prostata e di altra natura”.
In poche parole: partono dai dati diagnostici che hanno già, per ‘allenare’ le macchine a diagnosticare la malattia e selezionare il trattamento migliore.
3) Riconoscimento delle frodi in ambito asicurativo
Alcune importanti agezie assicurative stanno applicando sistemi automatici per il riconoscimento di frodi (o fraud detection).
I sistemi analizzano in maniera automatica le immagini ed identificano dei pattern per scoprire se ci sono dei falsi, delle richieste di rimborso fasulle, ecc.
4) Predizione delle azioni per la sicurezza urbana
Nell’ambito della sicurezza urbana esistono sistemi di “action-prediction” che riconoscono oggetti in movimento, e che analizzano il potenziale comportamento delle persone in giro per le strade.
5) Veicoli a guida autonoma
I sistemi di visione si trovano di più nei veicoli a guida autonoma, che combinano informazioni tramite, per esempio, i sensori di prossimità e la velocità massima per far stare l’auto in carreggiata ed intervenire con un arresto d’emergenza qualora servisse.
Come si installa un sistema di Computer Vision in azienda?
Possiamo dividere il funzionamento in tre capitoli:
1) Acquisizione dell’immagine,
2) Processo dell’immagine,
3) Analisi l’immagine per stabilire la reazione che dovrebbe avere la macchina.
Questi sono i 3 step che di solito applichiamo all’interno di nostra soluzione software.
Tutti questi tre processi sono diversi in base alla situazione industriale, al cliente e a molti altri fattori.
In prima battuta, l’acquisizione dell’immagine dipende da numerosi fattori:
► L’immagine/oggetto è esposto a sufficienza alla luce?
► In che condizioni si trova?
► A che velocità si trova?
► Si trova su un nastro trasportatore?
Nel momento in cui con il cliente si definisce dove verrà applicata la videocamera inizia la fase di studio per capire qual è la miglior videocamera, l’hardware migliore dedicato alla pura acquisizione dell’immagine.
Dopodiché inizia la fase di acquisizione che si concluderà quando avremo un’immagine standard.
Alla fine della prima fase, inizia la fase di processo dell’immagine.
Si tratta di eliminare o migliorare le caratteristiche dell’immagine in modo da facilitare l’apprendimento della macchina, del modello di Computer Vision.
C’è da dire che a volte non bastano ritagli o aumenti di definizione, ma ci possono essere processi più elaborati per ogni immagine.
Infatti, in questa fase entrano in gioco i data scientist e gli sviluppatori che estrapolano il valore aggiunto delle immagini.
Nella terza fase classifichiamo le immagini per preparare il dataset definitivo del modello, su cui faremo il training.
Dovranno essere definiti gli oggetti che la macchina deve riconoscere, le anomalie o i problemi che ha il prodotto in passaggio.
Una volta che le immagini sono state classificate e ordinate si procede al training del modello.
In pratica, si lascia la macchina a elaborare e rielaborare le immagini per definire il modello che avrà lo scopo preciso di trovare i difetti o delle specifiche caratteristiche.
Quando il modello è stato trainato si esegue tutta la parte di test e poi si inserisce il modello in un software che creiamo e che viene integrato con quello aziendale.
A questo punto il modello è pronto e si fanno delle prove pratiche per verificare se il modello funziona a dovere, dopodiché si passa in produzione.
Quanto tempo e quante immagini ci vogliono per avere un sistema di computer vision funzionante
Partiamo dal presupposto che ci sono due tipologie di aziende:
► Quelle che hanno un sistema di acquisizione immagini e quindi un dataset già pronto,
► Quelle che non hanno un sistema di acquisizione immagini e per questo non hanno un dataset.
Di per sè in nessuno dei due casi l’installazione di un sistema di Computer Vision è una cosa difficile o richiede troppo tempo, ma va fatta una specifica.
Nel caso in cui in azienda non è presente un sistema di acquisizione di immagine, allora bisogna costruirlo da zero.
Puoi capire bene che, senza immagini, è impossibile lavorare.
In questo caso bisogna trovare prima le condizioni ideali per scattare le foto e stabilire quali sono gli strumenti adatti per il lavoro (videocamere, fotocamere etc) grazie ad una rete di fornitori esperti a cui noi ci appoggiamo.
Di fatto, dobbiamo creare il dataset di immagini, proprio perché prima non esistevano.
E questo è un processo in più rispetto a quando c’è già un dataset.
La domanda (da un milione di dollari) che ci pongono i clienti di solito è:
Quante immagini vi dobbiamo dare per avere risultati soddisfacenti?
Dipende dalle caratteristiche che vogliamo cercare, dal tipo di modello che vogliamo creare, e altri fattori…
Di solito, ci vogliono tra le 1000 e le 2000 immagini per avere dei buoni risultati.
Chi di competenza potrebbe storcere il naso, mentre altri potrebbero dire: “Mamma mia quante immagini!”.
Il concetto essenziale è che più immagini ci sono e meglio è.
Naturalmente un sistema che deve partire da zero ha bisogno di immagini e casistiche che poi l’intelligenza artificiale dovrà acquisire e processare.
Dobbiamo partire comunque con il minimo indispensabile per avere già dei buoni risultati.
Su un sistema ‘da zero’ implica il fatto che dobbiamo avere il tempo di acquisire una quantità minima di immagini.
Chiaramente più immagini ci sono, più il modello diventa consistente.
Nel caso in cui ci sia già un sistema di acquisizione immagini e degli archivi, possiamo andare molto più veloci.
Non dobbiamo strutturare o progettare l’hardware, ma passiamo subito alla creazione del modello.
Di fatto si prende quello che è stato fatto negli ultimi 10 anni e gli si dà un valore aggiunto.
Su cosa stiamo lavorando noi di BlueTensor nell’ambito della Computer Vision?
Tiriamo fuori un caso interessante in ambito industriale, relativo al sistema di analisi dei difetti su pezzi prodotti in serie.
Il progetto prevedeva requisiti molto stringenti: identificare il 100% dei difetti sopra una certa dimensione, con una percentuale di falsi positivi inferiore al 10%.
La cosa interessante è che il cliente aveva già implementato degli algoritmi di image processing su queste immagini per identificare i difetti, ma ha ottenuto dei risultati non apprezzabili.
Un sistema per essere applicato in ambito industriale deve funzionare con percentuale di funzionamento sopra al 99%, altrimenti sarebbe inutilizzabile!
Un sistema che riconosce la metà dei difetti non va bene, tanto varrebbe continuare con l’operatore umano.
Siamo riusciti a risolvere il problema facendo uno studio approfondito sul modello da applicare e sugli algoritmi da sviluppare in ambito di image processing, combinati poi anche ad algoritmi di Deep Learning, dandoci dei risultati interessanti.
Un altro caso che abbiamo affrontato è un’analisi qualitativa del legno.
Con un’azienda specializzata nel settore abbiamo creato un sistema di analisi, quindi abbiamo progettato la parte hardware con i nostri fornitori.
Con l’esperienza dell’azienda abbiamo classificato il legno in base alla qualità e alla quantità di nodi presenti.
Il sistema poi identificava di fatto i nodi presenti sul legno che passava sul nastro sottostante.
Qui la criticità che abbiamo risolto è stata la velocità con cui dovevano essere analizzati identificati i modi.
Stiamo parlando comunque di 30 immagini al secondo che dovevano identificare l’asse di legno che stava passando sotto la videocamera.
Un piccolo consiglio per gli imprenditori…
Questo momento è l’ideale per pensare a come produrre di più e come produrre meglio, anche perché il tagliando si fa a macchina ferma…
Per la nostra esperienza, questo tipo di progetti, affinché diano risultati, presentano talmente tante variabili che difficilmente si trova una soluzione applicabile senza l’aiuto di un professionista.
La soluzione ottimale è costruire qualcosa di personalizzato, che non significa andare stravolgere le tecnologie esistenti, ma perlomeno mettere assieme le tecnologie esistenti nel migliore dei modi.
Stiamo parlando della parte di acquisizione, quindi la parte hardware, e soprattutto la parte software mettendo assieme i dati da algoritmi di Image Processing e gli algoritmi di Deep Learning.
Anche perché l’hardware per l’intelligenza artificiale cambia ormai ogni 3-6 mesi, e anche gli algoritmi cambiano velocemente…
Per cui un approccio ‘custom’ a questo tipo di problemi credo sia ottimale per le aziende.
Progetti simili non è che si installano e funzionano come un normale software…
Ha comunque la necessità di apprendere, di essere trainato, di acquisire delle informazioni base per poi dare la soluzione che un imprenditore si aspetta.
Per questo, meglio partire in anticipo e ragionare sull’avvio di un progetto in periodi come questi in cui c’è meno attività del solito.
Dove puoi trovarci?
Puoi prenotare una consulenza gratuita con noi cliccando QUI.
Oppure puoi telefonarci al numero verde 800 270 021, e noi saremo disponibili a dare informazioni su come implementare un sistema di computer vision.
A presto!
